PREMESSA
Post in via di sviluppo; fase iniziale di un processo che si costruisce nell’andare.
CURRICULUM DI PIERO PISTOIA :
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Questi ‘racconti’ di Statistica applicata di fatto sono modelli che automatizzano percorsi nell’analisi dei dati.
R è un programma potente e gratuito, continuamente aggiornato in tempo reale nelle principali Università del mondo. Sono disponibili centinaia di manuali gratuiti e migliaia di packages per tutte le esigenze.
Per vedere gli outputs anche grafici, le istruzioni (quando pronte girano!) possono essere riportate, con copia incolla, per es, prima sul Blocco Note o direttamente sulla console di R. Nel procedere potremmo anche decidere di alternare le istruzioni ai grafici (vedremo). Nota bene: prima di incollare in R, è necessario ripulire il piano di lavoro di R, premendo dal MENU MODIFICA ‘Pulisci console’ e poi dal MENU VARIE ‘Rimuovi tutti gli oggetti’
Questi primi dati di Larderello sono stati ripresi dalla “COMUNITA’ DI POMARANCE 1-1991” consegnati alla Redazione da Mauro Fanfani, allora Tecnico presso il laboratorio ENEL.
Quelli di Volterra furono forniti dal dott. Juri Bettini.
—————————————-
RIFLESSIONI SU UN ESEMPIO DI ANALISI STATISTICA CON R: MM DI PIOGGIA CADUTI IN OGNI ANNO DAL 1907 AL 1998 NELLA ZONA DI LARDERELLO (POMARANCE, Pisa). POSSIBILITA’ DI TRASFERIRE, CON POCHE MODIFICHE, IL PROCESSO SU ALTRE ANALOGHE SERIE STORICHE (Es., Volterra 1956-1986)
PRECISAZIONI SU REGRESSIONI LINEARI, MEDIE MOBILI, TESTS STATISTICI, INTERVALLI DI CONFIDENZA, FORECASTS ED ALTRO, OLTRE AL MODO PIU’ O MENO ORTODOSSO DI PROCEDERE.
dott. Piero Pistoia
Versioni del lavoro
PIOGGE_ANN_FORECAST_20_1_7.45
PIOGGE_ANN_20_1_LAPREVISIONE_ore17.45
PIOGGE_ANN_OUTPUTS_19.10
Si evidenziano i files richiamati e si copiano sulla console di R: iniziano automaticamente a girare; se incontrano un grafico si fermano in attesa di un tasto premuto o un click del mouse, permettendo di stampare o memorizzare il grafico stesso. Volendo possiamo anche con copia-incolla trasferire pezzi dell’articolo, per es., da un grafico all’altro. Infine è possibile ricopiare le istruzione direttamente sulla console di R.
——————————-
PARTE PRIMA CON INSERIMENTO DI OTTO PAGINE DI GRAFICI (FIG. 1-8) RIPRESI DAGLI OUTPUTS
Si ‘guarda’ dentro i dati ‘provocandoli’ con le istruzioni di R!
#ESEMPIO DI ANALISI STATISTICA CON IL LINGUAGGIO R: MILLIMETRI
#DI PIOGGIA CADUTI IN CIASCUN ANNO DAL 1907 Al 1990
#A LARDERELLO E DAL 1956 AL 1986 A VOLTERRA.
#PRECISAZIONI SU INTERVALLI DI CONFIDENZA ED ALTRA STATISTICA
#dott. Piero Pistoia
#IN QUESTO PRIMO INTERVENTO SI PROPONGONO UNA SERIE DI AZIONI
#MESSE IN ATTO PER PORRE PUNTI INTERROGATIVI AI DATI
#DA ANALIZZARE. NEI GRAFICI SI ‘LEGGONO’ LE RISPOSTE RESE DAI DATI.
#I dati originali erano a scansione mensile, ma noi inizieremo
#ad analizzare i dati annuali ottenuti sommando i 12
#valori mensili delle piogge per ogni anno.
#Se volessimo esprime un’ipotesi sulla pioggia caduta nell’anno
#in un certo intervallo di anni, quella più immediata
#è che la quantità di essa costruisca nel tempo una serie
#stazionaria, senza uniformità interne, (assenza di trend,
#fluttuazioni di circa uguale ampiezza) perché sosterremmo
#che sommare le entità mensili ridurrebbe le oscillazioni
#stagionali di tutti i livelli, mentre non è così immediato
#pensare a fenomeni atmosferici e/o astronomici che
#possano attivare oscillazioni annuali periodi o non periodiche
#(come, per es. i cicli undecennali delle macchie solari…)
library(“UsingR”); library(“TTR”);library(“tseries”);
library(“graphics”);library(“forecast”)
#Le librerie, se non esistono già nella biblioteca attuale della
#versione, devono essere prima caricate dal Menù.
par(ask=T)
par(mfrow=c(2,2))
#Da prove preliminari si evidenzia che nella serie originale di
#Larderello esistono almeno tre autliers: nel 1913
#(636 sostituito da 736.2), nel 1915 (1505.5 sostituito
#da 1145) e 1972 (539.2 sostituito da 739.2), pensando ad una
#serie più armonica internamente (gli autliers, essendo ‘accideni’
#isolati pesano meno nel forecast).
#Con pochi cambiamenti possiamo analizzare meccanicamente diverse
#serie storiche fornendo il vettore dati:
#proponiamo la serie di Larderello di 84 dato a partire dal 1907
#e quella di Volterra di 30 dati a partire dal 1956
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Piogge_annuali_1907_1990=
c(1174,915.7,1204.1,1203.6,891.5,950.6,836.2, 960.6,1145.5,
1142.2,1156.3,876.4,1045.9,968.0,750.8, 878.3,
719.5, 720.7, 1045.7,1198.1,904.2,1142.0,958.0,
914.4,952.1,1141.8,1023.1,966.6,1013.0,823.1,1138.1,
763.1,1102,1083.0,949.3,1054.2,741.2,804.9,814.8,964.6,
1236.2,829.6,1086.2,782.9,1153.8,877.8,780.4,799.4,800.7,
863.8,760.7,821.6,753,1175.6,873,857.4,1192.6,1276.4,
1117.3,1251.2,742.4,1023.8,1107.4,845.6, 769.4,739.2,
782.7,799.2,985.6,1163.4,826.0,880.4,1067.7,923.6,903.6,
856.6,855.6,1010.4,842.1,891.7,1061.8,783,739.3,1009.6)
#si chiude o si apre il vettore dati per analizzare un’altra serie
piogann907990=ts(Piogge_annuali_1907_1990) #si chiude per altro
#vettore dati dello stesso nome yt0
yt0=piogann907990 #si chiude o si apre
t=c(907:990)#si chiude o si apre
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
#Di seguito analizziamo la serie di Volterra di trenta dati dal 1956.
#Da prove precedenti consideriamo 2 autliers 1960 (1253)e 1984 (1156)
#interpolando con 1000 e 950 rispettivamente
#yt0=c(727,766,804,839,1000,892,866,968,957,1002,1042,727,954,1012,869,678,851,655,698,858,988,
#671,932,991,841,781,837,813,950,733,821) piogge annuali Volterra 1956-1986
#t=c(956-986) #si apre o si chiude
#yt0=ts(yt0) #si apre o si chiude
#Fig. 1 -> quattro grafici sulla stessa pagina: 1)(yt0,Time); 2)acf(yt0);
#3)hist(yt0); 4)punti dati e retta di regressione
#3)hist(yt0); 4)punti dati e retta di regressione
ts.plot(yt0)
#Osservando il grafico dei dati ad occhio ci turba notare un certa tendenza
#delle piogge a diminuire nel tempo,
#falsificando le aspettative se il fenomeno fosse corroborato.
acf(yt0)
hist(yt0)
#Osservando il grafico dei coefficienti di auto-correlazione h,
#sembra chiaramente che all’interno della serie
#non ci siano legami di causalità avvallando le aspettative.
#Applichiamo comunque un modello di regressione lineare semplice
#ai dati per un controllo.
# INIZIO DELL’ELABORAZIONE DEI DATI
# Si prova a cercare il package Using-R
#library(“UsingR”)
#library(“TTR”)
# Fitta i dati delle piogge col tempo in anni e fornisce gli autputs
t=c(1:length(yt0))
result=simple.lm(t,yt0)
summary(result)
#FIG. 2 -> #plot (result) fitta 4 grafici per l’analisi dei residui:
#1)Nel primo (Residual,fitted) si osserva la diffusione dei dati intorno
#alla linea y=0 e il trend che non è ovvio. 2)Nel secondo (Normal qqplot),
#i residui sono gaussiani se questo grafico segue da vicino la linea
#tratteggiata.
plot(result)
par(mfrow=c(1,1)) #da ora si plotta grafico per grafico.
fit=lm(yt0~t)
attributes(fit)
summary(fit)
fit$coefficients
fit$resid
#plot(lm(yt0~t))
pre=predict(fit)# valori sulla retta
pre # valori predetti
#FIG. 3 -> acf(pre)
acf(pre)
# Plotta i dati e la linea di regressione
ts.plot(yt0)
abline(fit)
#Opppure:plot(t,yt0); abline(result)
yt1=yt0-pre
#FIG. 4 -> nel piano cartesiano “yt0,time” viene disegnato l’intervallo
#di confidenza al 90% per la media. Ci sono due tipi di intervallo,
quello di ‘confidenza per la media’ e quello per la ‘predizione individuale’,
#naturalmente più grande. Consideriamo questi intervalli al 90%. Nel secondo
#vengono riportati ambedue gli intervalli
# INTERVALLI DI CONFIDENZA
#1
summary(fit)
#2
predict(fit,data.frame(t=sort(t)),level=.90, interval=”confidence”)
#3
ci.lwr=predict(fit,data.frame(t=sort(t)),level=.90,interval=”confidence”)[,2]
#4
points(sort(t),ci.lwr,type=”l”)
#5
ci.upr=predict(fit,data.frame(t=t),level=.90, interval=”confidence”,add=T)[,3]
#6
points(sort(t),ci.upr,type=”l”)
#FIG. 5 -> punti-dati con i due intervalli, di confidenza e di previsone, al 90%
# Si possono usare comandi di più alto livello del package UsingR di VENABLE
fit=simple.lm(t,yt0)
summary(fit)
simple.lm(t,yt0,show.ci=T,conf.level=0.90,pred=T) #fa un po’ casino!
#FACCIO DELLE PROVE DI ‘SMUSSAMENTO’
#Elimino una parte del contenuto dei files piogann908990
# (yt0) con una media mobile di ordine 5, pesata con 1,2,3,2,1 (Media Mobile 3*3)
#con comandi di basso livello e osservo quello che accade
#(confrontare con media mobile semplice 5)
#—————————
#SMUSSO5 pesato 1,2,3,2,1 (3*3)
m5=c()
for(i in 2:length(yt0)){
m5[i] =(yt0[i-2] +2* yt0[i-1] + 3*yt0[i] +2* yt0[i+1] + yt0[i+2])/9}
#prova a plottare m5
m5=ts(m5)
m5 # smusso5 la yt0 3*3; elimino dall’originale ciò che non è random!?
L’idea era solo sperimentare en passant, smussando con m5!
Da notare è che d’improvviso ho trovato cancellati i pesi dell’m5, sbilanciando risultati e grafici!!
#——————————
#Secondo ‘pezzo’ per cambiare vettore dati da sottoporre al prog.
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
#Attenzione! devo fare modifiche per scegliere fra i due vettori dati
#da analizzare
m5=m5[3:82] #per Volterra (31 dati) va da 3 a 29; PER LARDERELLO (84 DATI)
#DA 3 A 82
n5=length(m5)
yt=yt0[3:82] #in yt ci sono da 3 a 82 dati yt<yt0; per Volterra 3-29
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
par=(mfrow=c(2,2))
yt
nyt=length(yt)
nyt
par(mfrow=c(2,2))
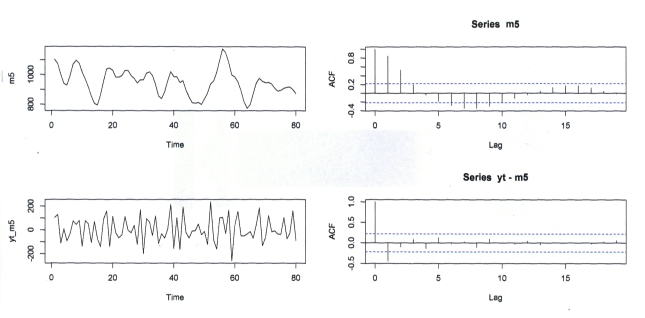
ts.plot(m5)
acf(m5)
yt_m5=yt-m5 #m5 e yt hanno la stessa lunghezza per cui si possono sottrarre
yt_m5 #originale meno m5_smussata
ts.plot(yt_m5)
lines(m5)
acf(yt-m5) # auto-correlazione di yt-smussamento 3*3
#Analizzo il vettore dati yt-m5 cercando la retta di regressione
t1=c(1:length(m5))
fit1=lm(yt_m5~t1)
summary(fit1)
La retta di regressione non esiste!
#FACCIO DELLE PROVE DI ‘SMUSSAMENTO’
——————————————————
# FIG. 6 -> 4 grafici sulla stesso piano: 1)graf. m5 (smusso 5 pesato 12321,3*3);
# 2)acf(m5); 3)graf. yt1=yt-m5 (yt è yt0 di lunghezza pari a m5 per sottrarre);
# 4)acf(yt1).
OSSERVAZIONI FUORI NORMA
Da osservare l’acf della serie yt-m5 : il picco fuori range può essere considerato dovuto a un caso accidentale come 1 su 20? e le oscillazioni smorzate dell’ acf di m5 non suggeriscono niente? Le armoniche di Fourier potrebbero ‘suonare’ qualcosa? Ritengo che non siano fuori luogo (anche se azzardate e deboli, ma cariche di significati scientifici, K. Popper, ipotesi ‘tentative’ o Tentative Theory) su oscillazioni super-annuali (di periodo circa 5, 11..?) relative ad armoniche rilevanti (si controllino anche i grafici di Fig. 7)
_________________________________
#TENTATIVI DI SMUSSAMENTO con SMA per raccogliere informazioni su #eventuali cicli super-annuali spesso periodici da analizzare con Fourier
piog3=SMA(yt0,n=3) #opero un semplice smussamento di ordine 3
piog5=SMA(yt0,n=5) # opero ora un semplice smussamento di ordine 5
piog8=SMA(yt0,n=8)
#piog11=SMA(yt0,n=11)
piog12=SMA(yt0,n=12) #opero un semplice smussamento di ordine 12
#piog15=SMA(yt0,n=15)
#ts.plot(piog3)
#ts.plot(piog5)
#ts.plot(piog8)
#ts.plot(piog12)
#smussa l’originale yt0 con 4 ordini (5 pesato 12312; 5;8;12)
par(mfrow=c(2,2))
#4 risultati dello smussamento di yt0: m5, 5, 8, 12
#FIG. 7 -> 4 grafici di smussamento sulla stessa pagina: 1)yt0 smussato m5;
#2)yt0 smussato 5; 3)yt0 smussato 8; 4)yt0 smussato 12.
ts.plot(yt0)
lines(m5,col=”orange”,lwd=2)
ts.plot(yt0)
lines(piog5,col=”orange”,lwd=2)
ts.plot(yt0)
lines(piog8,col=”blue”,lwd=2)
ts.plot(yt0)
lines(piog12,col=”red”,lwd=4)
#Osservando le ‘lisciature’ della curva_dati originale, sarebbe
#interessante sottoporre i vettori dati degli #smussamenti alla
#funzione del PERIODOGRAMMA (scritta dal dott. PIERO PISTOIA
#e testata e riportata nei diversi posts relativi ad esempi statistici a
#cura dello stesso scrivente: in particolare vedere “UN PARZIALE
#PERCORSO DI BASE SULL’ANALISI DI UNA SERIE STORICA
#REALE” dove tale funzione in .jpg è trasferibile e funzionante);
# per la ricerca di armoniche rilevanti.
#Non sembra così strano pensare ad influenze, per lo più
#periodiche, del Cosmo esterno sulla nostra atmosfera, con periodi
#maggiori di un anno terrestre. Anche l’Analisi di Fourier scritta
#col Mathematica di Wolfram, in più occasioni utilizzata dallo
#stesso autore, potrebbe essere uno strumento di controllo efficace.
#Si potrebbe anche riportare la Funzione _Periodogramma
#direttamente su questo post, per ogni possibile, anche futuro,
#utilizzo su qualsiasi vettore_dati.
par(mfrow=c(1,1))
#FIG. 8 -> 4 grafici di smussamento sullo stesso piano cartesiano (yt0,Time)
#Confronto 6 curve in un unico grafico (yt0,pre,m5,piog5,piog8,piog12)
ts.plot(yt0)
lines(pre)
lines(m5,col=”orange”,lwd=2)
lines(piog5,col=4,lwd=2)
lines(piog8,col=”blue”,lwd=2)
lines(piog12,col=”red”,lwd=4)
#Riflettiamo sullo smussamento interessante 12: sembra che esso tolga cicli super-annuali
#da investigarne in qualche modo le armoniche con fourier
# LA STATISTICA DI DURBIN WATSON
library(tseries)
y=yt0
n=length(y)
result=c()
result1=c()
for(t in 2:n){
result[t]=(y[t]-y[t-1])^2
}
result=result[2:n]
a=sum(result)
for(t in 1:n)
result1[t]=y[t]
b=sum(y)
dw=a/b
dw
#Possiamo usare anche funzioni di più alto livello caricando qualche #libreria nuova
#(‘lmtest’; attenzione alla versione di R!)
#PARTE SECONDA E IL PACKAGE ‘forecast’; si aggiungono
#6 pagine di grafici ripresi dagli outputs relativi
#Ci permettiamo di prendere un momento di riflessione in questo
#scorcio iniziale della PARTE SECONDA del nostro lavoro di
#’lettura’ dei dati. La retta di regressione apparsa ad occhio sui dati,
#dopo la regressione con i minimi quadrati di fatto ‘spiega’ ben poco
#del nostro campione (R-quadro trascurabile), ma se consideriamo
#le ‘statistiche campionarie T’ relative ai suoi coefficienti e le
#inseriamo sulle ascisse delle rispettive distribuzioni di Student,
#conosciute sotto l’ipotesi nulla, ci accorgiamo che probabilmente
#quella retta ‘esiste anche nell’Universo di tutti i campioni riferiti
#alla nostra ricerca. Così,nonostante questa retta non così ovvia,
#riteniamo ipoteticamente che: “se eliminiamo dai dati originali
#yt0, i valori della retta (pre), yt1=yt0-pre, già e ‘ricondizioniamo’
#il campione aggiungendo la media dei valori (cioè la media di yt0
#o di pre), otteniamo un valore migliore dell’originale almeno per
#l’applicazione del nostro modello di forecast (Simple Exponential
#Smoothing), cioè si rispetterebbero meglio i criteri di applicazione
#(omogeneità delle fluttuazioni col tempo, assenza di correlazioni
#interne…insomma migliore Stazionarietà)”. Tale ipotesi verrebbe
#controllata a posteriori con l’analisi dei residui. Basterà attribuire i
#valori della variabile ‘campione-condizionato’ alla variabile
#originale yt0 e procedere a far girare il programma successivo di
#previsione( yt0=campione-condizionato). Tale prova la qualche #lettore, se vorrà.
#yt1 era il vettore dei dati originali (yt0) meno le ordinate della retta
#(pre)
Myt0=mean(yt0); Mpre=mean(pre); Myt1=mean(yt1)
Myt0
Mpre
Myt1
#Dal plot di yt1
#Possiamo notare dal plot di yt1 che esiste un livello costante
#situato in corrispondenza ad valore di zero per la media; le
#fluttuazioni sembrano rimanere grossolanamente costanti nel
#tempo. E’ possibile probabilmente considerare la serie stazionaria,
#per cui si può tentare di usare un modello addittivo e uno
#’Smoothing Esponenziale Semplice’ per il forecast, forse con
#maggiore ‘matching’ di prima. Naturalmente bisogna
#’ricondizionare’ yt1 (centrata intorno alla media zero) alla serie
#originale. Riteniamo di poterlo fare aggiungendo ai valori di yt1, la
#media dei valori predetti ovvero dei valori originali; procederemo
#poi al solito a controllare questa scelta dal risultato (rilevanza del
#forecast)
Mpre=mean(pre)
yt0_condizionato=yt1+Mpre
#plotto yt0_condizionato insieme a yt0
FIG. 9′
ts.plot(yt0)
lines(yt0_condizionato,col=”blue”,lwd=2)
#Pongo:
#yt0=yt0_condizionato #per immettere nel processo_forecast i dati
#da cui si è tolto il trend rettilineo di dubbia rilevanza
#Noi però intanto riguardiamo il grafico originale yt0 da sottoporre,
#con A. Coghian, (A LITTLE BOOK OF R FOR TIME SERIES; release
#0.2), ad un processo di previsione.
ts.plot(yt0)
——————————————-
#PARTE SECONDA: LA PREVISIONE
#PREMESSA SUL ‘SIMPLE EXPONENTIAL SMOOTHING (SES)’
par(ask=T)
par(mfrow=c(1,1))
#Piogge_annuali_1907_1990=
c(1174,915.7,1204.1,1203.6,891.5,950.6,836.2, 960.6,1145.5,
1142.2,1156.3,876.4,1045.9,968.0,750.8, 878.3,
719.5, 720.7, 1045.7,1198.1,904.2,1142.0,958.0,
914.4,952.1,1141.8,1023.1,966.6,1013.0,823.1,1138.1,
763.1,1102,1083.0,949.3,1054.2,741.2,804.9,814.8,964.6,
1236.2,829.6,1086.2,782.9,1153.8,877.8,780.4,799.4,800.7,
863.8,760.7,821.6,753,1175.6,873,857.4,1192.6,1276.4,
1117.3,1251.2,742.4,1023.8,1107.4,845.6, 769.4,739.2,
782.7,799.2,985.6,1163.4,826.0,880.4,1067.7,923.6,903.6,
856.6,855.6,1010.4,842.1,891.7,1061.8,783,739.3,1009.6)
#Ridefiniamo yt0
#yt0= Piogge_annuali_1907_1990
#FIG. 9
#ts.plot(yt0)
#Le righe dei commenti associati al programma che segue devono essere
#scorciate (con cancelletti all’inizio) se vogliamo far girare il tutto dalla console di R!
#come accade nella prima parte di questo post; in caso contrario vanno riscritte le linee di programma
#in successione sulla console di R
#Il metodo del Semplice ‘Lisciare’ Esponenziale è raccomandato quando 1) i dati non
#presentano un trend ‘esplicito’ e, 2) non è coglibile una stagionalità.
#Da precisare che non si ha ‘trend esplicito’ anche quando si ha, sì, un cambiamento di livello
#o media nel corso del tempo fuori del random, ma tale evento si presenta poco regolare e
#intuibile, scarsamente razionalizzabile in un trend ‘esplicito’
#Sono almeno tre i possibili interventi nei processi di forecast del metodo SES , due
#praticamente immediati, il metodo ‘ingenuo’ , o ‘naive methods’, ‘average methods’
#(per prevedere è importante solo l’ultima osservazione che rimane costante nel tempo
#di previsione), l’altra, il metodo della ‘Media’ (i valori predetti sono tutti uguali alla media
#dei valori che servono per prevedere) e il terzo, più mediato, usa medie pesate, che tengono conto
#dei valori pesandoli in maniera diversa; quelli più lontani sempre meno di quelli più vicini
#secondo una curva esponenziale.
#Fra i modelli del terzo tipo utilizzeremo due modelli di HoltWinters con le funzioni di R HoltWinters()
#e forecast.HoltWinters(); per es., per Larderello: valori annuali 1907-1990; per Volterra valori
#annuali 1956-1986.
#RIASSUMIAMO IL PROCESSO
#Poiché riteniamo di avere una serie storica a cui si può applicare un modello addittivo con fluttuzioni
#pressochè costanti pressochè costanti e che possiede un livello che si mantiene, pensiamo, uguale
#nel tempo (valore medio) e nessuna stagionalità, possiamo usare uno dei tanti modelli SES (Simple
#Exponential Smoothing), per brevi previsioni future, cioè un mezzo per stimare i livelli previsti nei
#punti correnti col tempo.
#Se usiamo però un SES predittivo che utilizza la funzione HoltWinters() di R, sono necessari,
#per questo modello due parametri da immettere nell’argomento, beta e gamma che nella fattispecie
#dobbiamo uguagliare a FALSE (si cambia il loro valore, per es., per casi con trend e/o stagionalità),
#mentre calcola da sé il terzo parametro alfa, che controlla lo smoothing (alfa vicino a zero significa
#che diamo più peso ai dati recenti). Come outputs abbiamo il valore di alfa e tutti i valori previsti
#corrispondenti ai dati delle misurazioni originali (nella fattispecie 84) con cui è possibile costruire
#la curva di previsione all’interno dei dati.
#La funzione di HoltWinters() memorizza gli outputs in una lista di ‘oggetti’ da richiamare contenuta
#nella variabile ‘yt0previsti’ da noi scelta. Così la funzione HW() scrive i valori previsti (ed altro) in
#uno dela lista degli ‘oggetti’ (fitted, SSE…) contenuti nella variabile yt0previsti calcolata, per cui
#essi si troveranno nella variabile yt0previsti$fitted. Gli ‘errori della previsione’ si calcolano
#sottraendo dai valori predetti quelli osservati e l’oggetto SSE (Sum of Squared Errors),
#rappresenta una misura dell’accuratezza del forecast, fornito sempre dalla HW( ), che
# invece verrà richiamato da yt0previsti$SSE.
#E’ interessante notare che è necessario scegliere un valore iniziale di partenza per il calcolo
#dei livelli previsti; se questo valore non viene esplicitato il programma sceglie il primo valore
#dei dati.
#Ci sono anche dei processi per aiutarci a scegliere questo valore.
#Possiamo immettere però anche questo primo valore scelto da noi, aggiungendo il
#parametro ‘1.start’ nell’argomento della funzione HoltWinters(),
#HoltWinters(yt0, beta=FALSE, gamma=False, 1.start=X)
yt0previsti=HoltWinters(yt0,beta=FALSE, gamma= FALSE)
yt0previsti
#HoltWinters exponential smoothing without trend and without seasonal
#component.
yt0previsti$fitted
plot(yt0previsti)
FIG: 10
#La funzione HoltWinters() calcola i forecasts solo per i dati originali (nella
#fattispecie quelli da 1907 a 1990). Se vogliamo prevedere alcuni dati futuri
#(es., 8) è necessario scaricare il package di R ‘forecast’ , tramite library(‘forecast’),
#il quale contiene la funzione nuova ‘forecast.HoltWinters()’, che memorizzerà l’output
#nella variabile da noi scelta yt0previsti2 e aggiungeremo nel suo argomento
#’yt0previsti, h=8′
yt0previsti2 = forecast.HoltWinters(yt0previsti, h = 8)
#Con la funzione plot.forecast messa disposizione dalla libreria scaricata possiamo stampare
#le predizioni ottenute con la funzione forecast.HoltWinters():
plot.forecast (yt0previsti2)
#La funzione forecast.HoltWinters() dà la previsione per ogni anno con un intervallo di
#predizione all’80% (fascia arancionee) e al 95% (fascia gialla).
library(“forecast”)
FIG. 11
#La funzione HoltWinters() calcola i forecasts solo per i dati originali (nella
#fattispecie quelli da 1907 a 1990). Se vogliamo prevedere alcuni dati futuri
#(es., 8) è necessario scaricare il package di R ‘forecast’ , tramite library(‘forecast’),
#il quale contiene la funzione nuova ‘forecast.HoltWinters()’, che memorizzerà l’output
#nella variabile da noi scelta yt0previsti2 e aggiungeremo nel suo argomento
#’yt0previsti, h=8′
yt0previsti2 = forecast.HoltWinters(yt0previsti, h = 8)
#Con la funzione plot.forecast messa disposizione dalla libreria scaricata possiamo stampare
#le predizioni ottenute con la funzione forecast.HoltWinters():
plot.forecast (yt0previsti2)
#La funzione forecast.HoltWinters() dà la previsione per ogni anno con un intervallo di
#predizione all’80% (fascia arancionee) e al 95% (fascia gialla).
acf(yt0previsti2$residuals, lag.max=20)
FIG. 12
#Osservando l’acf dei residui può accadere che qualche ordinata superi la zona permessa
#(dove c’è assenza di autocorrelazione). Può essere che uno o due segmenti escano dai
#’significance bounds’. restando incerti se, fra 1-20 lags, ci sia qualche correlazione significativa.
#Per una conferma attiviamo il test in R di Ljung-Box-test che usa la funzione “ Box-test()”
#della libreria(stats):
#Box-test(yt0previsti2$residuals, lag=20, type=”Ljung-Box”)
#IL TEST DI LJUNG-BOX
#Se il p-value supera 0.05 di poco ci sarà una piccola certezza di qualche correlazione interna,
#che decideremo se sia dovuta al caso.
#E’ buona idea controllare anche la costanza della varianza e la normalità della distribuzione
#dei residui. Per la costanza della varianza facciamo il plot dei residui con il tempo.
plot.ts(yt0previsti2$residuals)
#Appare un grafico che presenta una successive di fluttuazioni col tempo. Può accadere a vista
#che in alcune parti del tempo l’ampiezza di esse risulti leggermente divers da quella di altre parti.
#Sarà da decidere se riteniamo che sia circa costante sostenendo l’ipotesi della uguaglianza
#della varianza col tempo
FIG: 13
#Per controllare infine se gli errori di previsione siano a distribuzione gaussiana con media zero,
#faremo in un istogramma (area coperta=1) degli errori con sovrapposta una curva gaussiana
#con media zero e deviazione standard pari a quella della distribuzione degli errori di previsione.
#Per far questo, di seguito viene riportata la routine di Avril Coghian di cui l’autore si sente debitore
#di questo scritto.
#Basta, dalla console di R, richiamare la funzione, scritta ad hoc, plotForecastErrors() con l’argomento
#’yt0previsti2$residuals’:
#INIZIO FUNZIONE PERSONALE
#plotForecastErrors=function(forecasterrors)
plotForecastErrors=function(forecasterrors)
{
#faccio un istogramma degli errori di previsioni
mybinsize=IQR(forecasterrors)/4
mysd=sd(forecasterrors)
mymin=min(forecasterrors)-mysd*5
mymax=max(forecasterrors)+mysd*3
#Genero una distribuzione di dati gaussiana con media zero e standard deviation
#pari a mysd
mynorm=rnorm(10000,mean=0, sd=mysd)
mymin2=min(mynorm)
mymax2=max(mynorm)
if (mymin2<mymin){mymin=mymin2}
if (mymax2>mymax){mymax=mymax2}
#Faccio un istogramma rosso degli errori di previsione con un gaussiana
#sovrapposta.
mybins=seq(mymin,mymax,mybinsize)
hist(forecasterrors, col=”red”, freq=FALSE,breaks=mybins)
#freq=F assicura che l’area sotto l’istogramma è = 1.
#genera una gaussian con media zero e standard deviation mysd
myhist = hist(mynorm,plot=FALSE, breaks=mybins)
#plotto una gaussiana blu sopra l’istogramma ddegli errori di previsione:
points(myhist$mids,myhist$density, type=”l”,col=”blue”,lwd=2)
}
#FINE FUNZIONE
plotForecastErrors(yt0previsti2$residuals )
#Possiamo usare questa funzione per costruire un istogramma con gaussiana
#degli errori di previsione per qualsiasi predizione delle
#piogge!
FIG. 14
e cambiando scala verticale:
#Da controllare se la distribuzione degli errori è grossolanamente centrata
#sullo zero, se è più o meno distribuita come una gaussiana, se è ‘skewed’
#da una parte rispetto alla curva normale, ecc.
#Comunque, a mio parere, è da sottolineare che questi nostri racconti di
#statistica nel loro articolarsi, non di rado si imbattono in scelte volontarie
#ed intuitive su grandezze in gioco e questo suggerisce che non è necessario
#poi in generale un atteggiamento troppo intransigente e restrittivo nelle
#valutazioni sulla rilevanza delle ipotesi.
——————————————-
40 916.8477 916.8477